- 会社情報
- プレスリリース
2012年3月29日
ビッグデータを高速に処理する
「分散ログ収集ソリューション」を提供開始
~ 従来のApache Flumeに比べて約200%超のパフォーマンス向上を実現 ~
ネットワークインフラ向けにミッションクリティカルシステム開発/コンサルティングを行う当社Acroquest Technology株式会社は、2012年3月29日、ログなどの大量テキストデータを高速に処理する「分散ログ収集ソリューション」の提供を開始しました。
本ソリューションでは、ログ収集を効率的に行うオープンソース・プロダクト「Apache Flume(以降、Flume)」に対し、独自の拡張を行うことで、従来に比べ、ログ収集処理のパフォーマンスを約200%に向上させました。
Flumeは、大量のログデータを収集・集約・移動することを目的に米Cloudera社が開発した、高い信頼性と可用性を持つ分散型のサービスです。
Cloudera社が提供するHadoopディストリビューション「CDH(Cloudera's Distribution for Hadoop)」に含まれるプロダクトであり、HBase、HiveとともにHadoopエコシステムの1つとして提供されています。
本ソリューションは、Flume+Hadoopで構成されており、数十~数百台のサーバからログを収集しHadoopのHDFSに蓄積する、分散ログ収集基盤を構築することが可能です。
今回、HDFSへのログ書込処理を担うFlume コレクター部に独自の拡張を行うことで、ログ収集処理のパフォーマンスを向上させました。分散ログ収集基盤の構成イメージを図1に示します。
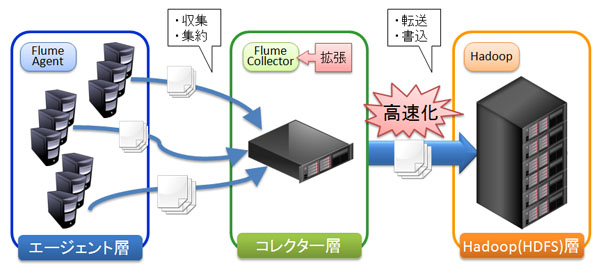
図1 分散ログ収集基盤の構成イメージ
また、今回実施した性能測定の条件・結果は、以下のようになります。
表1 性能測定の実施条件
| ハードウェア | 第数 | サーバースペック | |
|---|---|---|---|
| エージェントサーバ | エージェント×10 | CPU | 3.4GHz クアッドコアIntel Core i7 |
| メモリ | 16GB | ||
| コレクターサーバ | コレクター×1 | CPU | 3.1GHzクアッドコアIntel Core i5 |
| メモリ | 16GB | ||
| Hadoopクラスタ | マスターノード×1 データノード×6 |
CPU | 3.1GHzクアッドコアIntel Core i5 |
| メモリ | 16GB | ||
表2 ログ収集のスループット測定結果
| Flumeの信頼性モード | Flume (オリジナル) |
分散ログ収集基盤 (当社拡張) |
比率 |
|---|---|---|---|
| エンドツーエンド | 2,532 MB/分 | 6,015 MB/分 | 238 % |
| ディスクフェイルオーバー | 2,497 MB/分 | 5,575 MB/分 | 223 % |
| ベストエフォート | 2,445 MB/分 | 5,321 MB/分 | 218 % |
今回測定した構成で、約8TB/日のログ収集を可能にしていますが、サーバ構成はスケールアウト可能であり、要件に合わせてさらに大量のログを収集することも可能です。
Hadoopを代表とする大規模データ分散処理技術の進化にともない、企業内やインターネット上のビッグデータを分析し、リアルタイムの経営判断に活用するニーズが年々高まっています。
ビッグデータを処理するシステムに対し、「分散ログ収集ソリューション」を適用することで、大量ログの収集/集約/蓄積にかかる時間を劇的に効率化し、その結果、経営における意思決定をより迅速に行うことが可能となります。
今回、独自の拡張を行ったFlume コレクター部分は、オープンソースとして開発元にフィードバックを行う方針で、本ソリューションとしても無償ライセンスで提供する予定です。当社は、本ソリューションを利用した、分散ログ収集システム構築・導入のサポートサービスを3月29日より提供します。
費用は、規模や内容によって応相談となりますので、下記連絡先まで、お問い合わせください。
<本件に関するお問い合わせ>
Acroquest Technology 営業担当の槇 信之(マキ ノブユキ)までお願いいたします。
 TEL:045-476-3171 FAX:045-476-4171 E-mail:
TEL:045-476-3171 FAX:045-476-4171 E-mail: