
プログラミングとは?
1. 入力・処理・出力
次の問題を考えて見てください。
「5人の男性の年齢がそれぞれ21、18、22、19、20才のとき、その平均年齢を求めてください。」
この問題を解くのに皆さんは、全員の年齢の合計を求めて5で割ると答えるでしょう。これをもう少し詳しくいうと、
- (1) 全員の年齢の合計を求める
- (2) 合計を5で割る
この二つの手順で行います。
このように問題を解くときの手順をアルゴリズムといいます。皆さんがコンピュータに問題を解かせようと思ったとき、このアルゴリズムをプログラム言語で書いてあげなければなりません。このプログラム言語で書かれたアルゴリズムのことをプログラムといいます。
ところで、これが次のような問題だったらどうでしょう。
「5人の男性の平均年齢を求めてください。」
これでは一人ひとりの年齢が解りませんので平均の求め方は知っていても計算できません。アルゴリズムも必要ですが、それに使うデータも重要なものなのです。
年齢の20才、18才、人数の5人などは、プログラムを使って計算するときに必要なデータです。これを入力データといいます。また、平均年齢は計算の結果得られたデータです。これを出力データといいます。
プログラムは、次のことが解っていなければ作ることはできません。
- (1) 入力データは何か?
- (2) 出力データは何か?
- (3) アルゴリズムは何か?
2. 計算・記憶・判断
では、平均年齢を求めるプログラムを作りましょう。
- 年齢の合計を求める
- 合計を人数で割る
これではコンピュータは理解してくれません、コンピュータは「計算」・「記憶」・「判断」しか出来ませんので、変数や+、-、=(※)などを使った式だけで表してあげないといけません。
※ 「=」は、変数に対して実際にデータを関連付ける(代入する)ことを意味する。
- (1) 人数を記憶する変数・・・・・・num
- (2) 年齢の合計を記憶する変数・・・sum
- (3) 平均年齢を記憶する変数・・・・ave
とすると、先ほどの処理は次のようになります。
- num = 5 // 人数を変数 num に記憶
- sum = 0 // 変数 sum にゼロを記憶(初期設定)
- sum = sum + 21 // 変数 sum に5人の年齢を足し込む
- sum = sum + 18 // 〃
- sum = sum + 22 // 〃
- sum = sum + 19 // 〃
- sum = sum + 20 // 〃
- ave = sum / num // 合計を人数で割り平均年齢を求め、
// その結果を変数 ave に記憶する
3. プログラミングスタイル
それでは、実際にコーディングしてみましょう。コーディングとはプログラム言語でプログラムを書くことです。次の例は「C」というプログラム言語で書かれたものです。
average.c
| /* 5人の平均年齢を求めるプログラム */
#include <stdio.h> main()
num = 5;
sum = sum + 21;
ave = sum / num; printf("平均年齢:%d\n",
ave);
|
Cのプログラムは特別な場合を除き、小文字を使って書くことになっています。また、適当な位置から適当な間隔で書くことができます。これをフリーフォーマットと呼んでいますが、初めのうちは見やすさも考えて前の例に習って書いてください。
4. コーディング・コンパイル・実行
プログラムでコンピュータを動かすには、もう一つやっておかなければならないことがあります。
プログラム言語を機械語に翻訳しておかなければいけません。機械語とは1と0だけで書かれた言葉です。コンピュータは機械語しか解りません。
コンピュータには専属の通訳がいて、プログラム言語を機械語に通訳してくれます。この通訳をコンパイラと呼びます。
プログラム言語には、コンピュータを使う目的に応じてFORTRAN、COBOL、Pascal、Cなどいろいろ用意されています。
コンパイルすると実行できる機械語プログラムが出来ますので、それを実行することになります。
プログラムの構造
1. 基本構造
近年、ソフトウェアの巨大化に伴い、保守作業量が急速に増加しています。これに対応するには、読みやすく、修正しやすいプログラムを記述することが望まれています。そこで提唱されたのが、
「すべてのプログラムは3つの基本構造、すなわち順次構造、選択構造、反復構造のみで記述することができる」
という考え方です。
3つの基本構造とは以下のものです。
- (1) 順次構造
- 上から下へ記述された順に処理を実行する。
- (2) 選択構造
- 条件により実行する処理を選択する。多分岐でもよい。また、いずれか一方の処理のみでもよい。
- (3) 反復構造
- 処理を繰り返し実行する。終了判定は処理の前に行う場合と後で行う場合とがある。
これら3つの基本構造を組み合わせることによりプログラムを構築することが望ましいです。C言語はこれらの基本構造に沿ってプログラムが書けるように配慮されています。
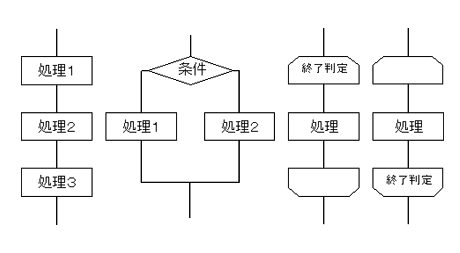
プログラム設計図の表記手段としては、古くからフローチャートがあり、現在でも一部で使われています。しかし、フローチャートの制約された表現手段からつくられる設計図は、フローがスパゲティ状に絡み合ってしまう、操作とデータを結び付けにくい、アルゴリズムがわかりにくい、などの多くの欠点が指摘されたにもかかわらず、広く使われてきました。
このことから、フローチャートに代わる記述法(構造化チャート)が各国で開発されてきました。どれもが基本的に、階層化されたプログラム設計図を記述しやすいものとなっています。
2. 構造化チャート
構造化チャートは、図形表現を導入し、プログラムの理論をわかりやすくしようとするものです。そのため、
- 処理の階層的表現
- データ構造の表現
- 処理の流れの表現
を記述する手段として提案されています。
構造化チャートの多くは、「処理の流れ」を主軸(縦軸)として、木構造で表現しています。詳細な処理内容は副軸(横軸)に展開します。
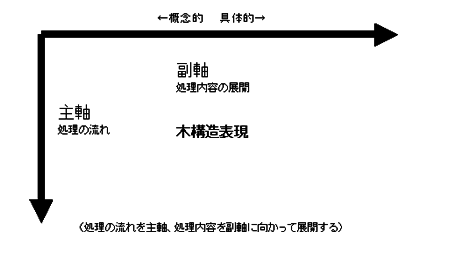
同様に、「データ構造」も木構造で表現することがあります。このような構造化チャートは、さまざまな記法のものが提案されています。以下にその代表例を示します。これらはすでに実務に使われているため、統一するのは非常に困難です。
|
|
|
| HCP: Hierarchical and ComPact description chart | |
| PAD: Problem Analysis Diagram | |
| SPD: Structured Programming Diagram | |
| YAC: Yet Another Control chart | |
| HIPO: Hierarchy plus Input Process Output | |
| NSチャート: Nassi Shnederman chart(Nassiらによる) | |
| DSD: Design Structure Diagrams | |
| PSD: Program Structure Diagrams(NSチャートと同じ) | |
| LCP: Logical Conception of Program flow chart |
プログラミングの手順
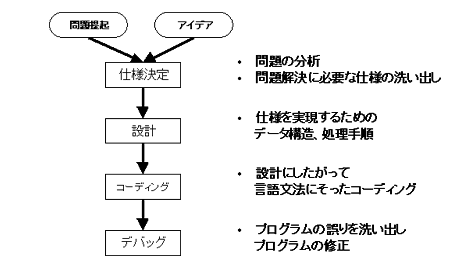
1. アイデアの具体化
プログラムを開発するのは、何か解きたい問題があるからです。まず、問題解決のアイデアがあって、それをコンピュータ上に実現したものがプログラムであると言ってもよいでしょう。このための問題解決のためのアイデアを良く練り、問題解決に必要な仕様を決定していく作業は非常に重要です。
プログラムがひき起こす不具合には、両極端の2つがあります。
(1) プログラムが問題解決に不十分な機能しか持たない
解きたい問題を検討する段階に不備があり、問題解決に必要な機能が十分検討されないままプログラムを開発してしまったことが主な原因です。
(2) プログラムに必要以上の機能を持たせてしまった
決定した仕様がオーバースペックな場合、プログラムの開発を非常に困難にします。不必要な機能を実現するために開発に時間がかかり、しかも開発されたプログラムは、より多くのバグを含む可能性をもってしいます。また、必要以上の機能はプログラムの使用方法を難しくし、場合によってはプログラムを汎用性のない魅力のないものにしてしまいます。
プログラムの仕様の決定は、非常に重要です。問題解決のアイデアをもとに、プログラムに対する要求を分析して、必要かつ十分な仕様を絞り込まなければなりません。この段階での検討が不十分なため生じたバグは、非常に根本的でプログラム全体にわたる修正を必要とする場合が多く、修正には大変な労力と時間を要します。
2. プログラムの設計
プログラムの流れは、入力・処理・出力といった順番が基本になります。
この流れをコーディングと比較してみると、入力の前に変数の型宣言が必要になります。
まずは問題文の中から、
- 与えられているもの(入力)
- 求めるもの(出力)
- 求め方(アルゴリズム)
をさがします。
次に上記要素から、
- 入力データを格納する変数
- 出力データを格納する変数
- それ以外の変数
を決めます。
「それ以外の変数」は次のようにして決めます。
- まずアルゴリズムを実現するために、必要な変数をすべて洗い出します。
- その中から、入力・出力データの変数を使えば必要なくなるものを除きます。
- これで残ったのが「それ以外の変数」です。
このような手順をふむことによって、一つ一つの変数を見つけることが出来ます。こうして見つかった変数は、その使い道をはっきりとさせ、それに見合った変数名を付けておく必要があります。とくに「それ以外の変数」は
- ワークエリアとして使うのか
- カウンタとして使うのか
- 配列の添字として使うのか
など入出力で使う変数のように、使い道をはっきりさせておきましょう。
そこで、変数名、使用目的などを一覧表にまとめておくとよいでしょう。
プログラムとは、結局のところコンピュータに対して実行すべき仕事の手順を書き示したものです。したがって、プログラムは最終的にはコンピュータに理解できる方法で示される必要があります。しかし、その本質は仕事の処理手順にあり特定のコンピュータや言語に依存しません。コンピュータは、「仕事がより小さな仕事の系列に分解でき、最終的には仕事の手順を簡単な命令の系列で書き表せる」という原理に基づいて作られています。
要求されている仕事を分析し、適切な命令の系列として記述することは難しいことです。しかし、仕事の手順が持つ性質について考えてみると、より合理的に仕事の手順を分析し、プログラムへと組み立てていく方法を見出すことができます。
一般的な仕事の手順を分析してみると、「順次構造」「選択構造」「反復構造」の3つの典型的な基本構造の組み合わせで成り立っています。どんなに複雑な仕事を考えても、すべて上記の3つの構造の組み合わせで書き表す事が出来るのです。この性質を用いれば、プログラムを単純な3つの構造の組み合わせとして設計することができます。
3. コーディング・デバッグ
コーディングとは何らかのプログラミング言語の文法にしたがって、プログラムを書くことです。多くの初心者が、コーディングのことをプログラミングであると考えがちですが、これはプログラミングの手順の一部に過ぎません。また、プログラムの設計がうまくいっていれば、コーディングはさして難しいものではありません。プログラムを読みやすくするためのプログラミングスタイルに関する一般的な注意事項をいくつか挙げてみます。
- 適切な字下げを行う
- 識別名は意味のあるものを使う
- 紛らわしい識別名は避ける
- カッコを積極的に利用する
- マジックナンバーを用いない
- コメントを付ける
デバッグ作業の要は、プログラムの検査です。プログラムの検査は、プログラムに対して何らかのテストを行い、その結果を検討することによって行われます。したがって、デバッグ作業をスムーズに行うためには、どのようなテストを行うかがもっとも重要な鍵となります。プログラムのテストを一言で定義すると次のようになります。
「プログラムの品質と信頼性を向上させるために、エラーを発見することを目的としてプログラムを実行すること。」
プログラム設計の手順
1. 段階的詳細化
プログラムの設計に着手したときに、最初から一度にプログラム全体を詳細に考えたり、具体的なことを考えることは事実上不可能です。たとえば、通常一つのコンパイル単位となる、数百から千数百行のプログラムを設計する場合を考えてみます。そのときに、いきなりコーディングできる細かさで、1行ずつ設計していくことは不可能です。
このことは、プログラム開発の経験のある方なら実感としてよく分かると思います。実際には、プログラムが果たすべき問題が与えられたときに、まず、おおまかに処理の手順を思い浮かべるのが自然な流れです。次に、そのおおまかな処理を詳細な処理の手順に分解し、これを繰り返してさらに詳細へと設計を行っていきます。
このように設計を行うことを、「段階的詳細化を用いて設計を進める」といいます。以下に段階的詳細化の具体的な方法を説明します。
(1) 第1段階
まず、一番上のレベルにおいてプログラムに要求された問題を果たすために、全体としてどのように実現するかを次の2ステップで検討します。
- 問題を実現するための要素を大まかに洗い出す
- 抽出した要素間に、実行順序を考慮した順次・選択・反復などの制御を付加する
この検討の結果、プログラムの課題を実現する個々の機能が明らかになります。
なお、要素を洗い出すときは、その規模や性質から考えて、出来るだけ対等になるようにする。また、問題の大きいプログラムを設計する場合には、ここで抽出した要素はプログラムの問題の大きさに比例して、当然粗くなります。
(2) 第2段階
第1段階で明らかになった個々の機能のうち、詳細化の必要なすべての機能を一つずつ取り上げて、そのおのおのについてどのように実現するかを検討します。この段階の検討も第1段階と同様に「要素の抽出」と、「制御の付加」の2ステップで行います。これにより、この第2段階の機能が明らかになります。
第3段階以降は、前の段階で明らかになった機能それぞれについて、第2段階と同様の検討を繰り返していくことになります。このようにして、しだいに細部へと進めていけば、最後にはコーディングできる詳しさに到達するはずです。
2. 段階的詳細化の利点
段階的詳細化を用いて設計を行う方法の利点は、次の通りです。
(1) 問題を抽象的にとらえ、それを徐々に詳細化・具体化できる
与えられた課題からいきなり具体的なことを考えるのは不可能に近いです。最初は抽出すべき要素やその要素の性質を、抽象的なレベルでとらえから個別に具体化していくことにより、一度に考える範囲を限定して設計を進めることができます。
(2) 対象領域を絞り、不必要な情報を隠すことにより、局所化しやすくなる
範囲を限定して考えることにより、そのときに設計を行っている範囲に無関係な、余計な情報はほとんど考慮する必要がなくなります。これにより、設計している範囲の独立性が高まり、局所化しやすくなります。
(3) 詳細決定を延期できる
そのときに検討している範囲よりさらに細かい事項はひとまず保留しておいて、1段下のレベルまで延期する事ができます。このため、同時に検討する複数の事項は重要度や質を同じものとすることができ、効率の良い検討を行うことができます。
(4) 単純化・簡素化ができる
段階的詳細化によって設計された末端の処理はきわめて単純で、独立性が高く、わかりやすいものになります。
最後に、構造化された、わかりやすいプログラムの設計方法についてまとめると、次のようになります。
「段階的詳細化+基本三構造の組み合わせ」で行う。ただし、基本三構造ばかりにとらわれて形式的な構造化を行ったりすると、かえってわかりやすさを損なうことがあります。読みやすさを最大の要件と考えて、制御構造を全体として確保することが大切です。
3. プログラム設計図の利点
趣味でプログラムを作るのでない限り、フローチャートや木構造チャートなどのプログラム図を作成してからコーディングすることが、現在では当たり前になっています。プログラム図を用いて設計を行う具体的利点は、次の通りです。
(1) 論理的に正しいプログラムを早く作成できる
設計しながらコーディングするのではなく、まず、プログラム図を書いて設計を行い、論理的な正しさに確信を持ってからコーディングを行います。このほうが、正しく動作するプログラムを作成する近道であるといえます。
(2) 設計の際に書いた図が設計ドキュメントとして残る
設計を行いながら作成したプログラム図が、そのまま設計ドキュメントになります。詳細なドキュメントは、デバッグやプログラムの保守を行うときに役に立ちます。
(3) プログラミング言語を意識しないで設計を進めることができる
一般に、プログラム図は特定の言語に依存しないで記述できるので、詳細設計段階ではプログラミング言語にとらわれないで論理を追及することができます。
(4) コーディングの誤りと詳細設計の論理的誤りを識別できる
プログラム図で表現した詳細な設計ドキュメントがあれば、誤りの性質を容易に見分けることができます。
モジュール分割
1. モジュール化の概念
モジュール化の考え方はプログラミングに限らず、さまざまな分野で使われるものです。ここでは、モジュールの概念を簡単に述べるだけにとどめます。
設計作業とは、「分割:分解」と「組立:統合」です。私たちは、どのような問題解決であっても、一度に全体を取り扱うよりは、より小さく、思考しやすい大きさに分割しています。プログラミングでは、おおもとを「主モジュール」、分割されたそれぞれを「下位モジュール」と呼び、個々のプログラム単位を独立させます。さらに「下位モジュール」も大きすぎれば同様に分割し階層構造化します。
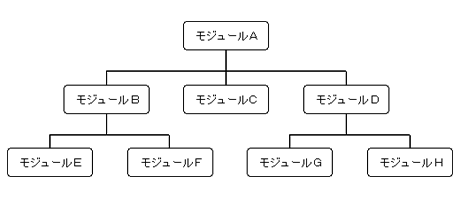
したがって、トップモジュールは概念的な記述内容でよく、下位になるほど段階的に詳細な記述になります。これが「トップダウン・プログラミング」と呼ばれる手法です。「手続きに着目」して階層化した場合、下位になるほど他のモジュールとの相互作用が強くなる傾向があります。これに対して「データに着目」してモジュール化を進めるアプローチがあります。組立は、下位の構成要素であるモジュールを合成する作業であり、分割と逆の過程です。これは、トップダウンプログラミングで定義された下位モジュールを統合し、部分プログラムからプログラム全体へとまとめていく過程であり、「ボトムアップ」手法と呼ばれます。
このように、「トップダウン・プログラミング」は「ボトムアップ」と対にして、よく使われます。
2. モジュール間のインターフェース
モジュール間の従属関係でいえば、「上位モジュール」が「主モジュール」となり、「上位モジュール」が「下位モジュール」を利用することになります。モジュールを使うとき、「上位モジュール」は「下位モジュール」を「呼び出す」あるいは「コールする」といいます。このとき、モジュール間ではデータ(パラメータ)のやり取りを行います。
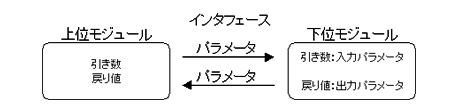
- (1) モジュール概要(処理)
- (2) 引き数(入力)
- (3) 戻り値(出力)
3. 問題の解析と明確化
実際のプログラム作成の前には、目的とする仕事を明確にし、大まかな処理ステップに書き下ろす必要があります。ここでいう処理ステップとは、フローチャートなどで代表される図記法で構成される各ステップではなく、目的に対してどのような処理をどのように構成すべきかを示す構想設計のためのメモです。
実際にコンピュータを利用する処理では、多量のデータを扱う場合が多く、この場合、取り扱うデータをどのようなデータ構造にするかによって、問題解決のためのアルゴリズムの構成が異なってきます。データ構造とアルゴリズムは密接な関係があり、データ構造の適切な選択がよいプログラム作成につながります。そのため、構想設計時にはデータの流れに十分注意する必要があります。
機能分割
1. 機能分割
モジュール分割の最も一般的な方法は、プログラム(主機能)を機能部分に分ける「機能分割」です。
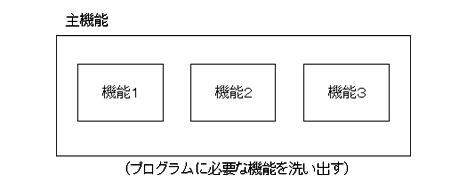
プログラムに必要な機能を洗い出し、それぞれの機能の違いを明示します。ここで、主機能が主モジュール、洗い出された要素機能がサブモジュールです。
分割された機能は、さらに「独立性」のある小単位の機能に分割します。これを繰り返し、分割不能なところまで展開します。
機能分割によって分割された機能要素どうしは、「相互作用」が少ないものです。したがって、それらの機能要素は別々に設計することが出来ます。このことは、ある部分に変更が生じたとき、該当する部分だけの修正で済むことになるので、「変更容易性」が向上することになります。また同時に、「再利用性」や「テスト容易性」などが高まります。
機能分割のための指針をいくつか次に示します。
- (1) 機能の流れが連続になるように分割する。
- (2) 機能が選択的になるように分割する。
- (3) 機能が繰り返しになるように分割する。
- (4) 入力、処理、出力とを明確に区分するように分割する。
- (5) 判断や決定機能は上位レベル、処理動作の機能は下位レベルになるように分割する。
- (6) 機能間でやりとりするデータは出来るだけ少なくするように分割する。
- (7) 各々の機能は単一の入口、単一の出口を持つように分割する。
2. 分割法
(1) TR分割法
トランザクション(TRansaction:入力するデータ)の種類によって異なった(選択的)処理を行うとき、それぞれの処理単位に分割する方法です。
これによって分割されるモジュールは、それにあてられたトランザクションのみ処理をすればよく、他のトランザクションについて注意を向ける必要がないため、独立性の高いものになります。
(2) STS分割法
データの流れに着目し、データのソース(源泉)、トランスフォーム(変換)、シンク(吸収、結果出力)に分割する方法です。
まず、必要とされる部分機能を洗い出し、データの流れに沿って部分機能をバブル(bubble:丸印)で表して並べます。バブルの中には機能名を入れ、データの流れを矢印で示し、データ名を簡潔に記入します。そしてデータ入力の最大抽象点と出力の最大抽象点を見出します。最大抽象点を基準にすると、3つのSTSモジュールが決定します。
入力の最大抽象点とは、入力データを左から右方向に眺めていき、処理されたデータが入力データとみなされなくなった点です。
出力の最大抽象点とは、出力データを右から左方向に眺めていき、処理されたデータが出力データとみなされなくなった点です。
機能分割の基準
1. 機能分割の基準
(1) 大きさの尺度
モジュールは管理可能な大きさにしなければなりません。一般的にソースプログラムにして1ページなどといいますが、あまり小さくしてしまうと小単位の機能を実現できないことがあります。
(2) インターフェースの単純さ
モジュールを細分化すると個々のモジュールは簡素化されますが、インターフェースが複雑になる傾向があります。したがって、モジュールを制御する「プログラム構造」の設計に負担がかかります。逆に細分化が浅い場合は、インターフェースの設計が少なくて済みますが、モジュール単体の機能が増えて汎用性が乏しくなります。
理想は「単一データが単一の入口から」「単一データが単一の出口に」ですが、現実的には複数データをやり取りすることが多くあります。できればインターフェース要素は2から3要素にとどめておくことが望まれます。
(3) 結合の尺度
モジュール間のインターフェースを単純にすれば、モジュールの独立性を高めることが出来ます。「モジュール間のインターフェース」を結合の尺度として分類できます。結合度の一番弱い「データ結合」が理想的です。
| 内容結合 | 他のモジュールのデータを直接アクセスする |
| 共有結合 | 共通の外部データ構造をアクセスする |
| 外部結合 | 共通データの不必要なデータをマスクする |
| 制御結合 | モジュール機能の制御データを渡す |
| スタンプ結合 | データ構造をパラメータとして渡す |
| データ結合 | 単体データをパラメータとして渡す |
(4) 強度の尺度
モジュールはある1つの明確な機能を持つように分解するのがよいのです。もしも複数の機能を1つのモジュールに凝縮するなら、個々の機能は互いに関連性がなければなりません。「モジュール内部の関連性」をモジュール強度として分類できます。強度の強いほどモジュールの機能が明確で独立性が高くなります。
| モジュール内の機能間に関係がない | |
| 類似する複数の機能を持つ | |
| 論理的で、時間の近接する複数の機能を持つ | |
| 複数の機能を順次実行する | |
| 手順的で、機能間にはデータの関連がある | |
| 1つのデータ構造を複数の機能が扱う | |
| 1つの機能だけを持つ |
